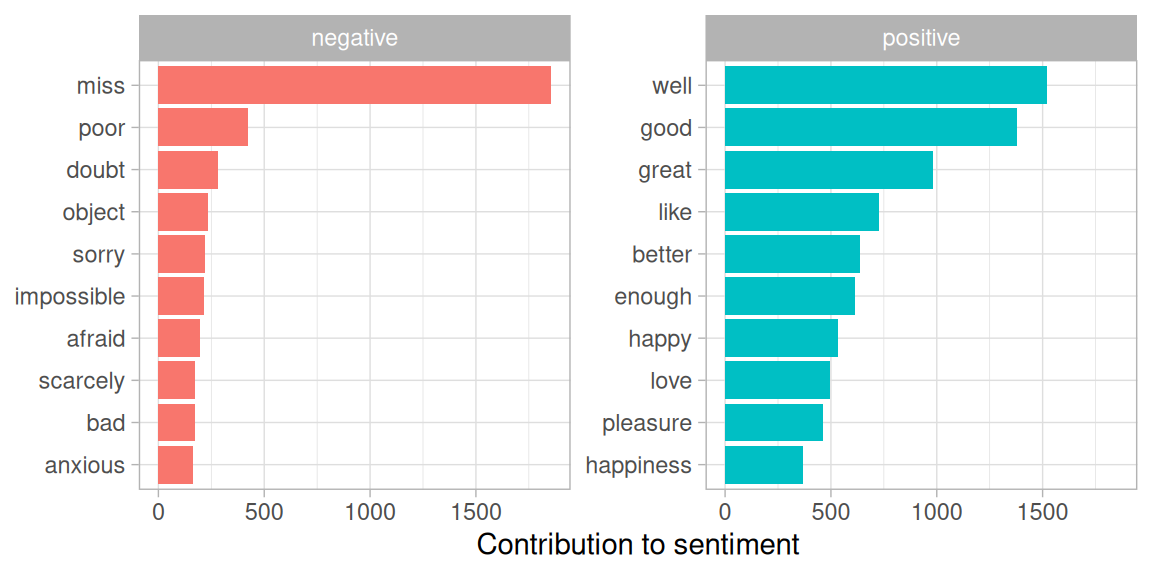
# A tibble: 2,585 x 3 word sentiment n <chr> <chr> <int> 1 miss negative 1855 2 well positive 1523 3 good positive 1380 4 great positive 981 5 like positive 725 6 better positive 639 7 enough positive 613
接著我們可以透過 ggplot2 呈現結果
1 2 3 4 5 6 7 8 9 10 11
bing_word_counts %>% group_by(sentiment)%>% top_n(10)%>% ungroup()%>% mutate(word = reorder(word, n))%>% ggplot(aes(word, n, fill = sentiment))+ geom_col(show.legend =FALSE)+ facet_wrap(~sentiment, scales ="free_y")+ labs(y ="Contribution to sentiment", x =NULL)+ coord_flip()
這邊值得一提的是,在負面情緒裡面的第一個 miss 反而是被當作為負面詞,而這不太符合目的。可以利用 bind_rows() 把這樣的詞加進自定義停用詞裡,我們定義這個欄位為 lexicon。