前面一章 是解釋說明什麼是 tidy text 文本格式,並且顯示文本裡面詞頻狀況比例最高的有哪些詞,而這篇文來調查不同的主題,做進一步的挖掘,探討情感分析。也就是說,再看一本書時,除了看哪些單字是用了最多,更多得是需要了解本文在對於請感方面的用詞詞彙做推斷,理解本文內的資料是正面或者是負面的情緒,在本篇的介紹大綱裡面包含如下:
學習內容大綱
sentiments 數據集
使用內部聯接 (inner_join) 進行情感分析
對三個情感字典進行比較
一樣是透過 tidy 工具的優勢可以很容易的得知本文內的情感情形。
sentiments 數據集 我們透過 tidytext 套件,就可以直接使用 sentiments 數據集裡面包含了好幾個情感的字典。
1 2 3 library( tidytext) sentiments
結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 27,314 x 4 word sentiment lexicon score <chr> <chr> <chr> <int> 1 abacus trust nrc NA 2 abandon fear nrc NA 3 abandon negative nrc NA 4 abandon sadness nrc NA 5 abandoned anger nrc NA 6 abandoned fear nrc NA 7 abandoned negative nrc NA
這邊有三個通用性質的詞典為:
AFINN: Finn Årup Nielsen bing: Bing Liu and collaborators nrc: Saif Mohammad and Peter Turney
這三個詞典都是單獨的詞,裡頭包含了很多英語詞,而且也有正面或負面情感的分數。tidytext 提供了 get_sentiments() 函數可以取得特定的詞典,比如 afinn 就輸入
結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 2,476 x 2 word score <chr> <int> 1 abandon -2 2 abandoned -2 3 abandons -2 4 abducted -2 5 abduction -2 6 abductions -2 7 abhor -3
而 bing 的部分
結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 6,788 x 2 word sentiment <chr> <chr> 1 2-faced negative 2 2-faces negative 3 a+ positive 4 abnormal negative 5 abolish negative 6 abominable negative 7 abominably negative
再來是 nrc 的部分
結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 13,901 x 2 word sentiment <chr> <chr> 1 abacus trust 2 abandon fear 3 abandon negative 4 abandon sadness 5 abandoned anger 6 abandoned fear 7 abandoned negative
是不是呈現的結果,sentiment 欄位都有所不同呢? nrc 詞典把詞按照了是/否 標註在各個類別當中,比如正面、負面、情緒、期待、開心、悲傷等等。bing 詞典把二元歸於正面和負面的類別而已,也就是 negative 或者 positive。而 AFINN 詞典則是把每個詞分配成 -5~5 分之間的值,負數代表負面情感,正整數代表正面情感。
使用內部聯接 (inner_join) 進行情感分析 我們一樣使用 janeaustenr 套件電子書做範例的介紹,對於 tidy text 的格式,情感分析是可以在內部關聯 (inner join) 方式完成。
好的,可以看看 nrc 詞典中帶點有快樂分數的單字,另外就是設定每一個單詞都是來自於哪一個章節,在這裡使用了 group_by 以及 mutute 來建造這些結果。
1 2 3 4 5 6 7 8 9 10 tidy_books <- austen_books( ) %>% group_by( book) %>% mutate( linenumber = row_number( ) , chapter = cumsum ( str_detect( text, regex( "^chapter [\\divxlc]" , ignore_case = TRUE ) ) ) ) %>% ungroup( ) %>% unnest_tokens( word, text)
以下可以看看 Emma 最開心的詞是什麼?,結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 725,055 x 4 book linenumber chapter word <fct> <int> <int> <chr> 1 Sense & Sensibility 1 0 sense 2 Sense & Sensibility 1 0 and 3 Sense & Sensibility 1 0 sensibility 4 Sense & Sensibility 3 0 by 5 Sense & Sensibility 3 0 jane 6 Sense & Sensibility 3 0 austen 7 Sense & Sensibility 5 0 1811
我們從 unnest_tokens() 中列出了 word 的列,另外在情感詞典也有一個是 word 欄位的名稱,因此執行連結方面更容易許多
好的,現在本文呈現也滿整齊整理單詞了,這樣子就可以開始做情感分析。首先是用 nrc 詞典和 filter() 得到 joy 的詞,再用 filter() 得到 Emma 這本書,然後再用 inner_join() 執行情感分析做將詞做聯合起來。最後使用 dplyr 裡的 count() 看看開心的詞有哪些。
1 2 3 4 5 6 7 nrc_joy <- get_sentiments("nrc") %>% filter(sentiment == "joy") tidy_books %>% filter(book == "Emma") %>% inner_join(nrc_joy) %>% count(word, sort = TRUE)
結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 303 x 2 word n <chr> <int> 1 good 359 2 young 192 3 friend 166 4 hope 143 5 happy 125 6 love 117 7 deal 92
在結果呈現裡面可以看到多數的正面詞,比如 good、young、friend。
另外,我們也可以使用 Bing 詞典和 inner_join() 找到每個詞的情感得分,並計算出正面與負面的數量。
我們定義 index 來紀錄敘事的進程,採用這個索引按每 80 行文本做累加。會用 80 行當作基準點是因為太小的段落可能無法得到比較好的情感估值,太大的話會影響到敘事結構。之後用 spread() 在不同的列中得到正面和負面的情感,最後計算情感差距 (正面-負面)。
1 2 3 4 5 6 7 library( tidyr) net_sentiment <- tidy_books %>% inner_join( get_sentiments( "bing" ) ) %>% count( book, index = linenumber %/% 80 , sentiment) %>% spread( sentiment, n, fill = 0 ) %>% mutate( sentiment = positive - negative)
結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 920 x 5 book index negative positive sentiment <fct> <dbl> <dbl> <dbl> <dbl> 1 Sense & Sensibility 0 16 32 16 2 Sense & Sensibility 1 19 53 34 3 Sense & Sensibility 2 12 31 19 4 Sense & Sensibility 3 15 31 16 5 Sense & Sensibility 4 16 34 18 6 Sense & Sensibility 5 16 51 35 7 Sense & Sensibility 6 24 40 16
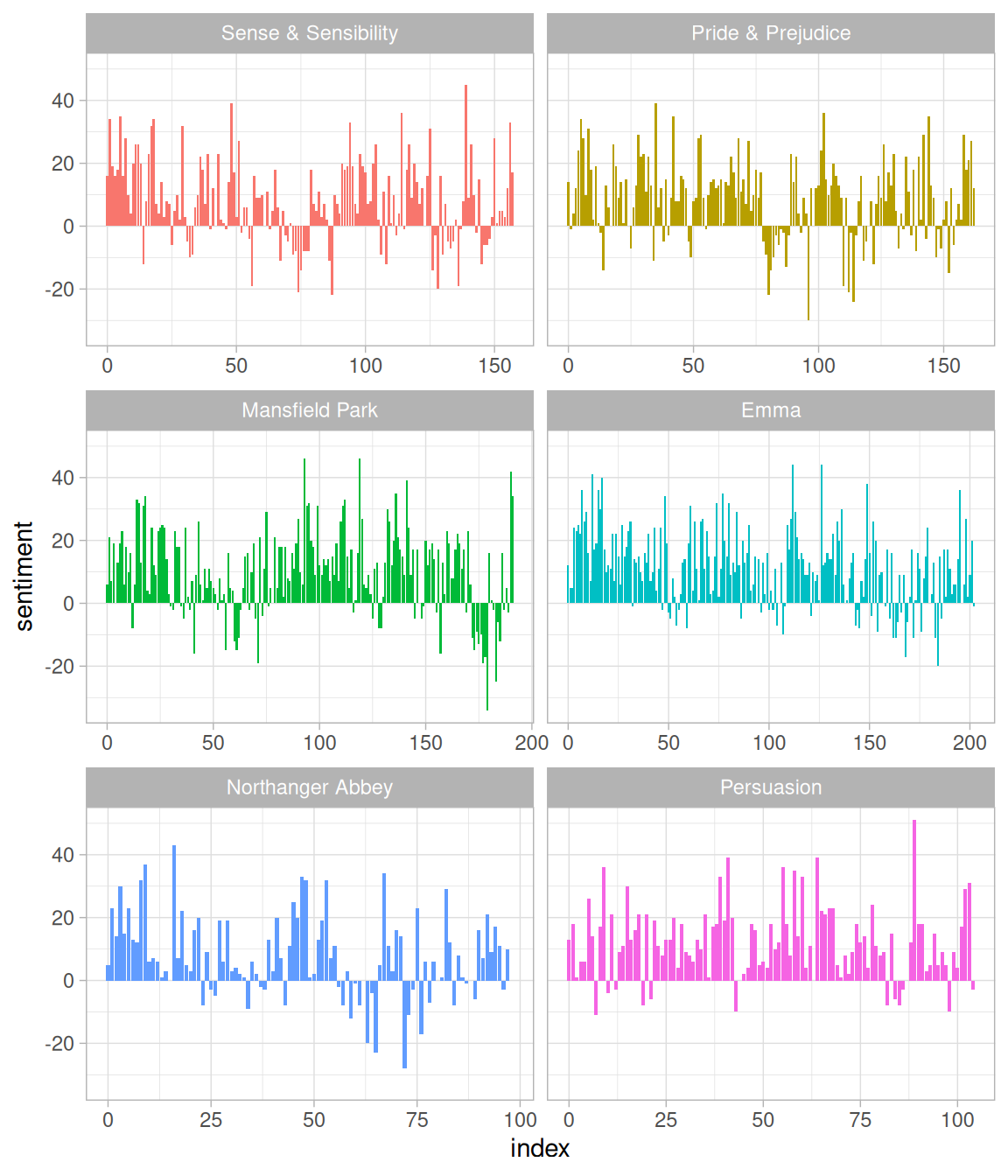
好的,接著下來就可以拿這份結果分別繪製出情感分值的圖。在這裏採用 ggplot2
在這份圖當中就可以看到故事的發展變化,看起來正向的情緒滿多的。
對三個情感字典進行比較 前面我們介紹了三個情感詞典,分別是 bing, nrc, AFINN 這三套。本章節就用這三套來介紹,看看情感的變化如何。首先,使用 filter() 選出書上的 傲慢與偏見 Pride & Prejudice 這本書來做講解。
1 2 3 4 pride_prejudice <- tidy_books %>% filter( book == "Pride & Prejudice" ) pride_prejudice
顯示結果如下:
1 2 3 4 5 6 7 8 9 10 # A tibble: 122,204 x 4 book linenumber chapter word <fct> <int> <int> <chr> 1 Pride & Prejudice 1 0 pride 2 Pride & Prejudice 1 0 and 3 Pride & Prejudice 1 0 prejudice 4 Pride & Prejudice 3 0 by 5 Pride & Prejudice 3 0 jane 6 Pride & Prejudice 3 0 austen 7 Pride & Prejudice 7 1 chapter
跟前面所提到的相同,現在使用 inner_join() 用不同的方法來計算情感,同樣的使用 count, spread(), mutate() 計算出每一段本文的情感狀況
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 afinn <- pride_prejudice %>% inner_join( get_sentiments( "afinn" ) ) %>% group_by( index = linenumber %/% 80 ) %>% summarise( sentiment = sum ( score) ) %>% mutate( method = "AFINN" ) bing_and_nrc <- bind_rows( pride_prejudice %>% inner_join( get_sentiments( "bing" ) ) %>% mutate( method = "Bing et al." ) , pride_prejudice %>% inner_join( get_sentiments( "nrc" ) %>% filter( sentiment %in% c ( "positive" , "negative" ) ) ) %>% mutate( method = "NRC" ) ) %>% count( method, index = linenumber %/% 80 , sentiment) %>% spread( sentiment, n, fill = 0 ) %>% mutate( sentiment = positive - negative)
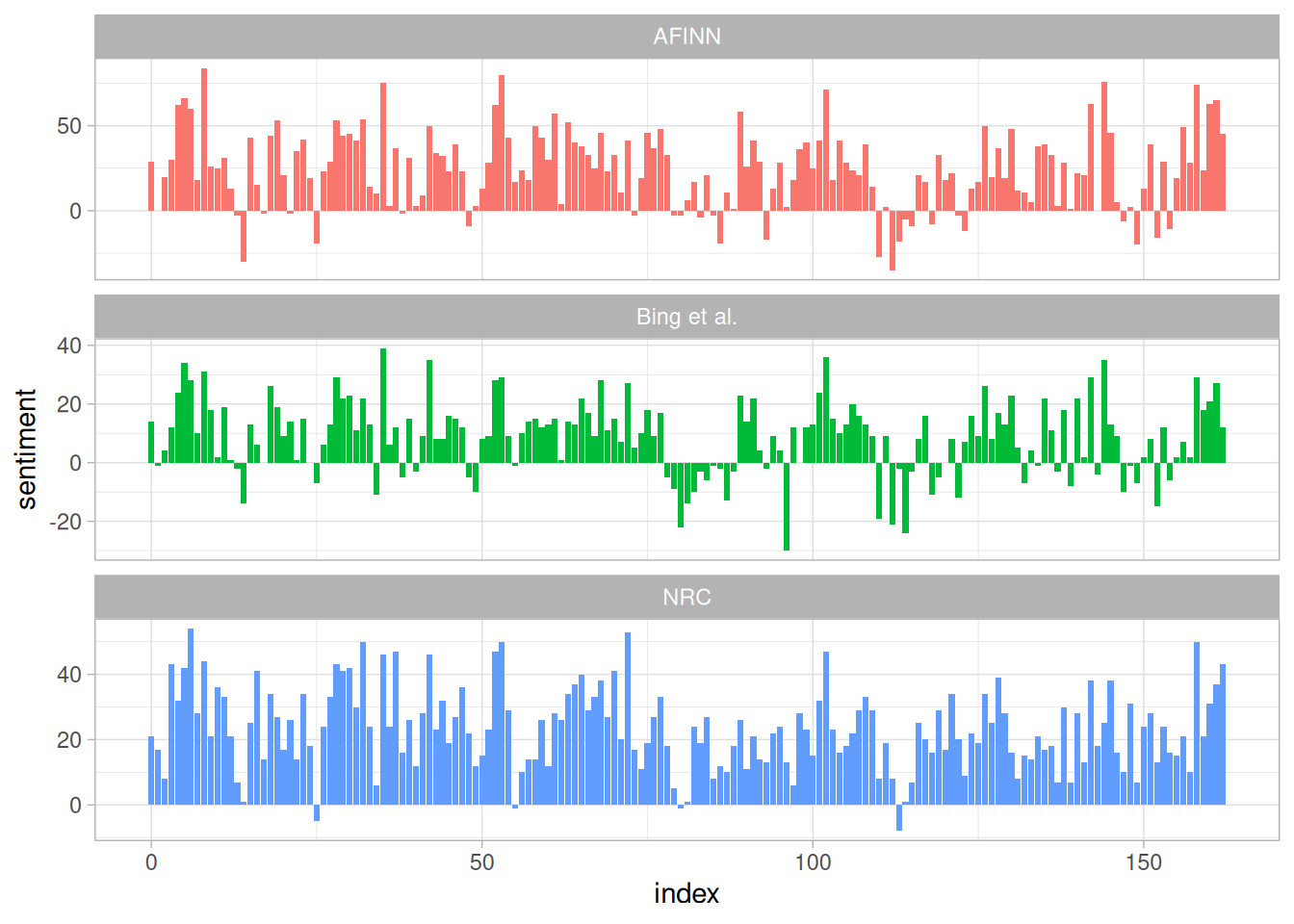
有了三個比較之後,就用圖示的方式顯示結果
用了這三個情感詞典給出的結果卻很不相同,但整體看小說的變化事實上有相似的軌跡。在 AFINN 給的最大絕對值,具有高的正直,Bing 標記出連續的正面或是負面。NRC 的話相對於其他結果更高,情緒方面更高,這三者詞典都表達出了透過故事的弧線整體的趨勢走向。
然而,為什麼 NRC 詞典在結果上面有這麼高的情緒比例呢?我們可以看到一下,nrc 與 bing 的正面與負面詞數有多少。
1 2 3 4 get_sentiments( "nrc" ) %>% filter( sentiment %in% c ( "positive" , "negative" ) ) %>% count( sentiment)
結果如下:
1 2 3 4 5 # A tibble: 2 x 2 sentiment n <chr> <int> 1 negative 3324 2 positive 2312
那 bing 的部分呢?
1 2 get_sentiments( "bing" ) %>% count( sentiment)
結果如下:
1 2 3 4 5 # A tibble: 2 x 2 sentiment n <chr> <int> 1 negative 4782 2 positive 2006
可以從這裡得知,負面詞也都滿多的,尤其是 bing 的負面詞比 nrc 高。所以在做情緒分析時,需要考慮到這三個詞典的差別,看看這個在故事的路徑發展下是否吻合。
情感分析先介紹到這裡
參考
Text Mining with R