學習內容大綱
- gutenbergr (古騰堡電子書)
- 詞頻 (Word frequencies)
gutenbergr (古騰堡電子書)
gutenbergr 套件是一個可以存取公領域的電子書。進入 古騰堡計畫網站,載入你感興趣的電子書籍,主要可以使用 gutenberg_download() 函數,參數則輸入 id 或者多部的電子書作品。
以下的例子,就從 古騰堡計畫網站 找個四本 H.G. Wells 寫的書做介紹,分別是
- The Time Machine
- The War of the Worlds
- The Invisible Man
- The Island of Doctor Moreau.
用 Top 100 頁面也可以找一些比較流行的電子書 點選這裏查看
詞頻 (Word frequencies)
首先使用 gutenbergr 套件,並且再用 gutenberg_download() 下載四本電子書
1
2
3
4
5
| install.packages('gutenbergr')
library(gutenbergr)
hgwells <- gutenberg_download(c(35, 36, 5230, 159))
|
下載完畢之後,我們第一件事情就是把詞作分詞,然後移除停用字 (anti_join(stop_words))
1
2
3
4
5
| tidy_hgwells <- hgwells %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)
tidy_hgwells
|
此時,資料結果如下,包含了 gutenberg_id 與 word 欄位:
1
2
3
4
5
6
7
8
9
10
11
| # A tibble: 66,734 x 2
gutenberg_id word
<int> <chr>
1 35 time
2 35 machine
3 35 1898
4 35 time
5 35 traveller
6 35 convenient
7 35 speak
...
|
清除停用字之後,我們看看常用字的比例如何
1
2
3
4
| tidy_hgwells %>%
count(word, sort = TRUE)
tidy_hgwells
|
H.G. Wells 詞頻次數結果如下:
1
2
3
4
5
6
7
8
9
10
| # A tibble: 11,769 x 2
word n
<chr> <int>
1 time 454
2 people 302
3 door 260
4 heard 249
5 black 232
6 stood 229
7 white 222
|
然後,我們在找另一個不同風格的作家 Brontë sisters
1
2
3
4
5
6
7
8
9
10
| bronte <- gutenberg_download(c(1260, 768, 969, 9182, 767))
tidy_bronte <- bronte %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)
tidy_bronte %>%
count(word, sort = TRUE)
tidy_bronte
|
Brontë sisters 詞頻次數結果如下:
1
2
3
4
5
6
7
8
9
10
| # A tibble: 23,050 x 2
word n
<chr> <int>
1 time 1065
2 miss 855
3 day 827
4 hand 768
5 eyes 713
6 night 647
7 heart 638
|
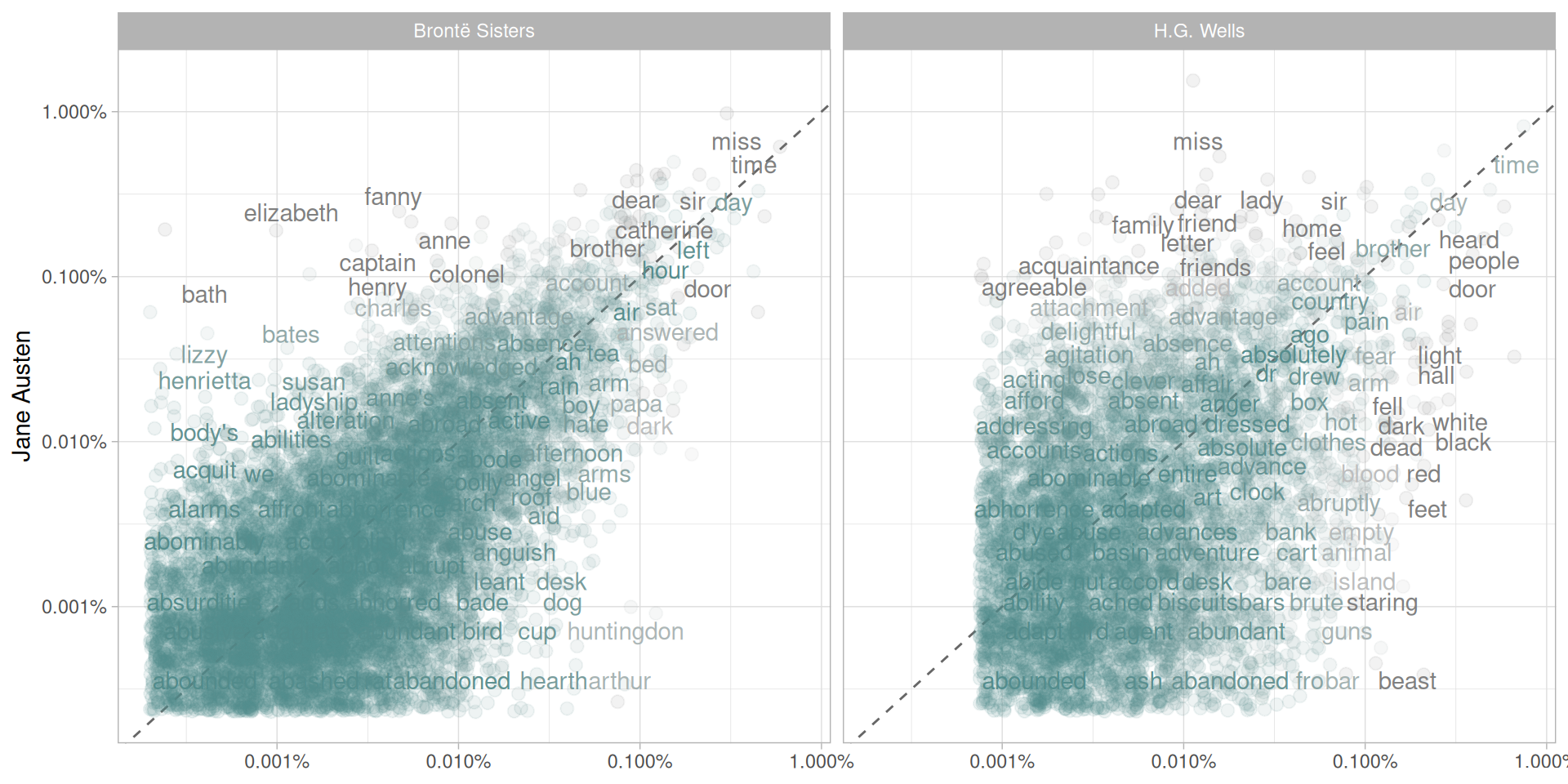
可以看到詞頻次數,time, eyes 等經常使用的詞。那麼,透過 data frames 綁定一起計算每個單詞的頻率,繪製三套小說的結果。
分別是三個變數:tidy_bronte、tidy_hgwells、tidy_books
1
2
3
4
5
6
7
8
9
10
11
12
| library(tidyr)
frequency <- bind_rows(mutate(tidy_bronte, author = "Brontë Sisters"),
mutate(tidy_hgwells, author = "H.G. Wells"),
mutate(tidy_books, author = "Jane Austen")) %>%
mutate(word = str_extract(word, "[a-z']+")) %>%
count(author, word) %>%
group_by(author) %>%
mutate(proportion = n / sum(n)) %>%
select(-n) %>%
spread(author, proportion) %>%
gather(author, proportion, `Brontë Sisters`:`H.G. Wells`)
|
古騰堡計畫 UTF-8 編碼有一些是有下底線的單詞,而這個通常用來強調。
1
2
3
4
5
6
7
8
9
10
11
12
13
| library(scales)
ggplot(frequency, aes(x = proportion, y = `Jane Austen`, color = abs(`Jane Austen` - proportion))) +
geom_abline(color = "gray40", lty = 2) +
geom_jitter(alpha = 0.1, size = 2.5, width = 0.3, height = 0.3) +
geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5) +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
scale_color_gradient(limits = c(0, 0.001), low = "darkslategray4", high = "gray75") +
facet_wrap(~author, ncol = 2) +
theme(legend.position="none") +
labs(y = "Jane Austen", x = NULL)
|
![]()
此圖可以看得出來兩組文本裡面具有相似的頻率,比如 Jane Austen 和 Brontë 的文本裡面有 miss, time, day 以及 Jane Austen 和 Wells 文本裡面有 time, day, brother 頻率狀況
參考
- Text Mining with R