# A tibble: 73,422 x 4 text book linenumber chapter <chr> <fct> <int> <int> 1 SENSE AND SENSIBILITY Sense & Sensibility 1 0 2 "" Sense & Sensibility 2 0 3 by Jane Austen Sense & Sensibility 3 0 4 "" Sense & Sensibility 4 0 5 (1811) Sense & Sensibility 5 0 6 "" Sense & Sensibility 6 0 7 "" Sense & Sensibility 7 0 8 "" Sense & Sensibility 8 0 9 "" Sense & Sensibility 9 0 10 CHAPTER 1 Sense & Sensibility 10 1 # … with 73,412 more rows
# A tibble: 725,055 x 4 book linenumber chapter word <fct> <int> <int> <chr> 1 Sense & Sensibility 1 0 sense 2 Sense & Sensibility 1 0 and 3 Sense & Sensibility 1 0 sensibility 4 Sense & Sensibility 3 0 by 5 Sense & Sensibility 3 0 jane 6 Sense & Sensibility 3 0 austen 7 Sense & Sensibility 5 0 1811 8 Sense & Sensibility 10 1 chapter 9 Sense & Sensibility 10 1 1 10 Sense & Sensibility 13 1 the # … with 725,045 more rows
在這個結果可以看到每一行的值,有一些沒有意義的詞,比如 the, of, to, by 這種字詞,在 tidytext 數據集裡有 stop_words 存有停用詞,就可以使用 anti_join() 將停用詞移除
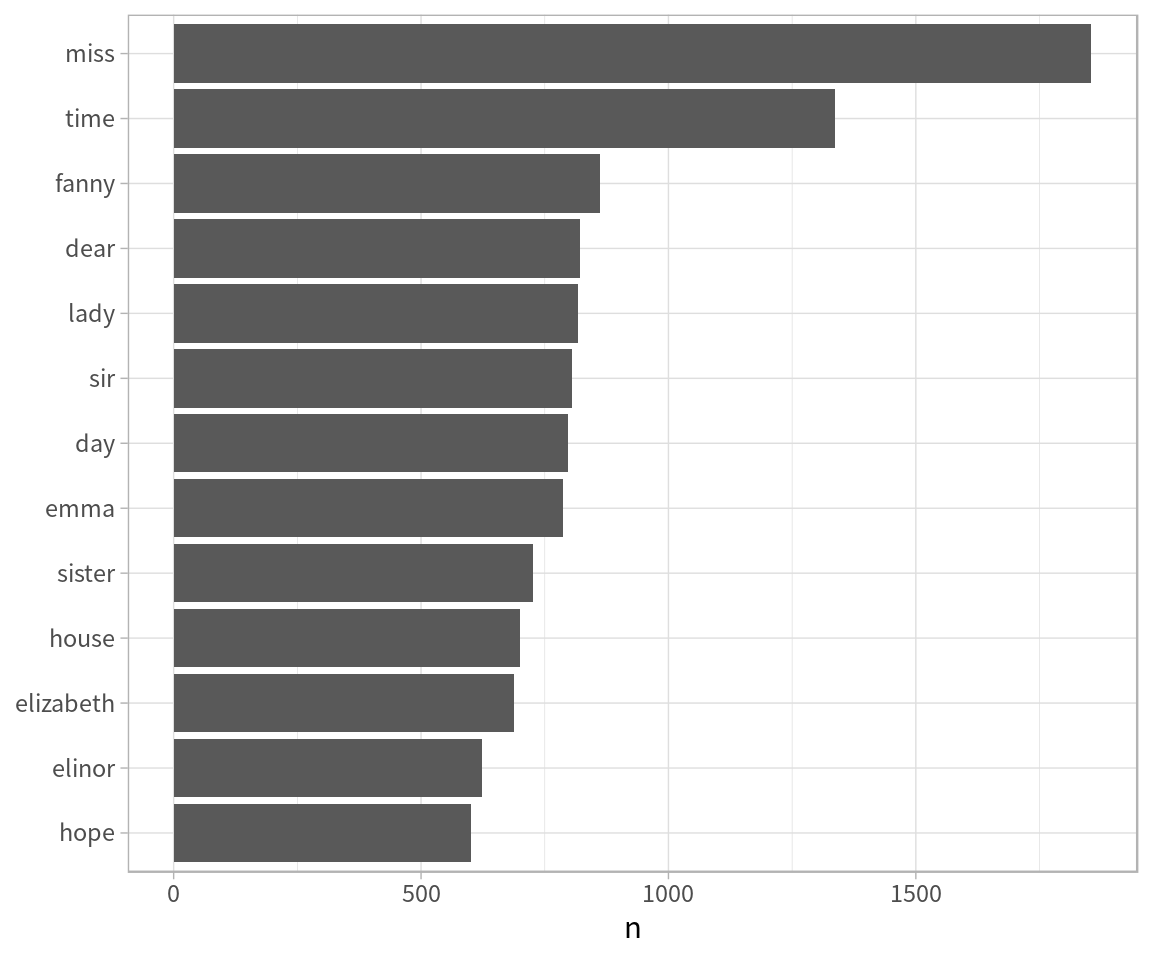
# A tibble: 13,914 x 2 word n <chr> <int> 1 miss 1855 2 time 1337 3 fanny 862 4 dear 822 5 lady 817 6 sir 806 7 day 797 8 emma 787 9 sister 727 10 house 699 # … with 13,904 more rows
另外我們還可以轉成視覺化的圖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
install.packages('ggplot2') library(ggplot2)
# 從上述的常見詞頻次數來看, 用數字是很難看出明顯的差距, 可以用圖片的方式呈現更能夠表達 tidy_books %>% # 由於要製作柱狀圖, 我們把上述詞頻 word 做個數量 count(word, sort =TRUE)%>% # 篩選 n 欄位大於 600 次數的, 600 以下因為太少則忽略 filter(n >600)%>% mutate(word = reorder(word, n))%>% # 在 ggplot 定義 x, y 軸,分別是 word 與 n ggplot(aes(word, n))+ geom_col()+ xlab(NULL)+ coord_flip()